本地部署deepseek-r1

AI-摘要
Tianli GPT
AI初始化中...
介绍自己 🙈
生成本文简介 👋
推荐相关文章 📖
前往主页 🏠
前往爱发电购买
本地部署deepseek-r1
钱涛模型参数
deepseek-r1模型不同参数的特点,适用场景及硬件配置如下,根据自己实际情况选择对应版本。
| DeepSeek 模型版本 | 参数量 | 特点 | 适用场景 | 推荐硬件配置 |
|---|---|---|---|---|
| DeepSeek - R1 - 1.5B | 1.5B | 轻量级,参数量与规模小 | 短文本生成、基础问答等轻量级任务 | 4 核处理器、8G 内存,无需显卡 |
| DeepSeek - R1 - 7B | 7B | 性能与硬件需求较平衡 | 文案撰写、表格处理、统计分析等中等复杂度任务 | 8 核处理器、16G 内存,Ryzen 7 或更高 CPU,RTX 3060(12GB)或更高显卡 |
| DeepSeek - R1 - 8B | 8B | 性能略优于 7B 模型 | 代码生成、逻辑推理等高精度轻量级任务 | 8 核处理器、16G 内存,Ryzen 7 或更高 CPU,RTX 3060(12GB)或 4060 显卡 |
| DeepSeek - R1 - 14B | 14B | 高性能,擅长复杂任务 | 长文本生成、数据分析等复杂任务 | i9 - 13900K 或更高 CPU、32G 内存,RTX 4090(24GB)或 A5000 显卡 |
| DeepSeek - R1 - 32B | 32B | 专业级,性能强大 | 语言建模、大规模训练、金融预测等超大规模任务 | Xeon 8 核(80GB)或更高配置 |
| DeepSeek - R1 - 70B | 70B | 顶级性能,适合大规模与高复杂计算 | 多模态任务预处理等高精度专业领域任务,适用于预算充足的企业或研究机构 | Xeon 8 核、128GB 内存或更高,8 张 A100/H100(80GB)或更高 |
| DeepSeek - R1 - 671B | 671B | 超大规模,性能卓越、推理快 | 气候建模、基因组分析等国家级 / 超大规模 AI 研究及通用人工智能探索 | 64 核、512GB 或更高,8 张 A100/H100 |
本人部署的是8b版本,可以做到流畅推理。
部署
安装ollama
进入ollama官网,点击download后,选择对应电脑系统进行下载安装
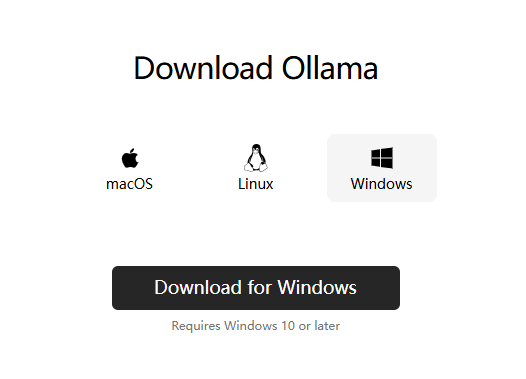
下载模型
回到ollama官网,在搜索栏中搜索deepseek-r1
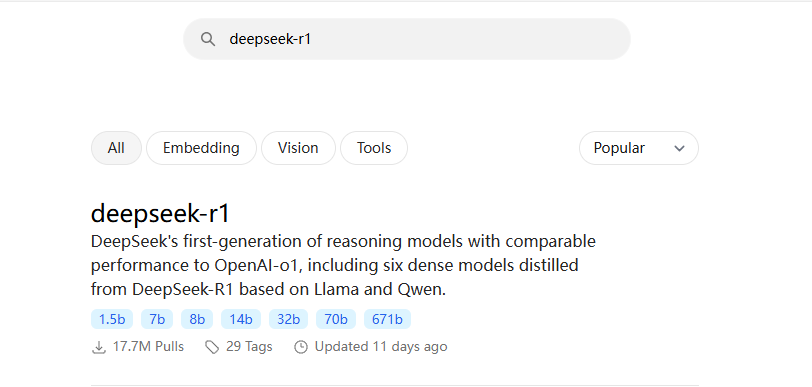
选择对应参数模型,复制指令。
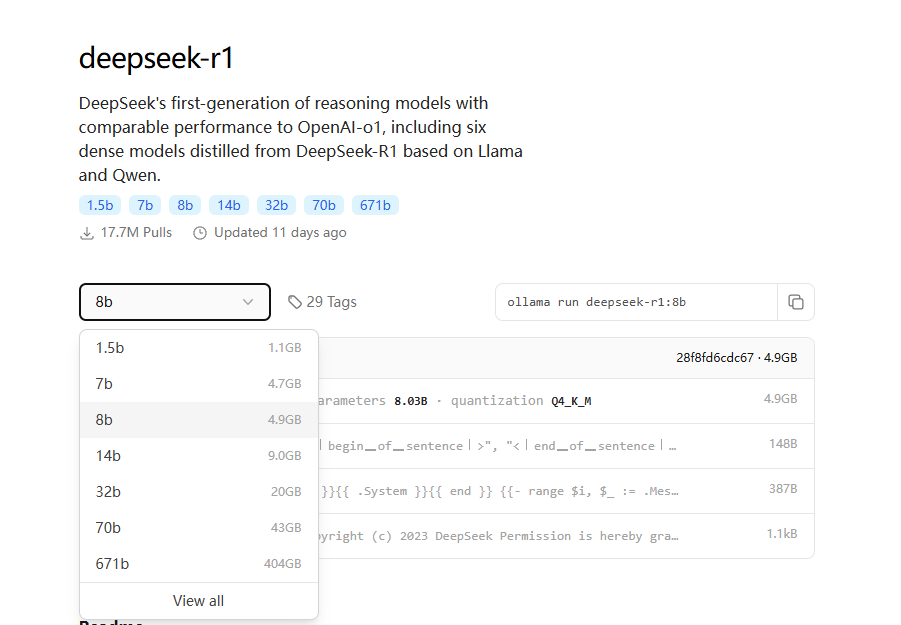
这里选择8b的模型,以管理员身份打开终端,运行复制的指令。
1 | ollama run deepseek-r1:8b |
等待模型下载安装完成。后续在终端中执行刚才的指令,就可以调用该模型来推理了。
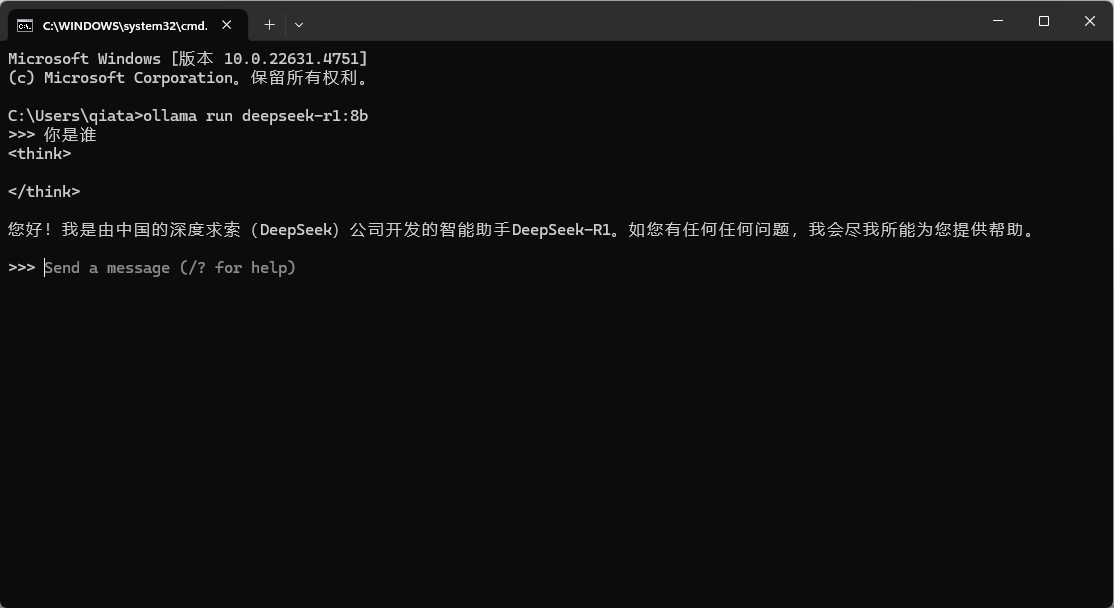
虽然现在已经可以正常进行推理了,但是终端界面始终不是特别友好,因此需要一个可视化的界面
可视化
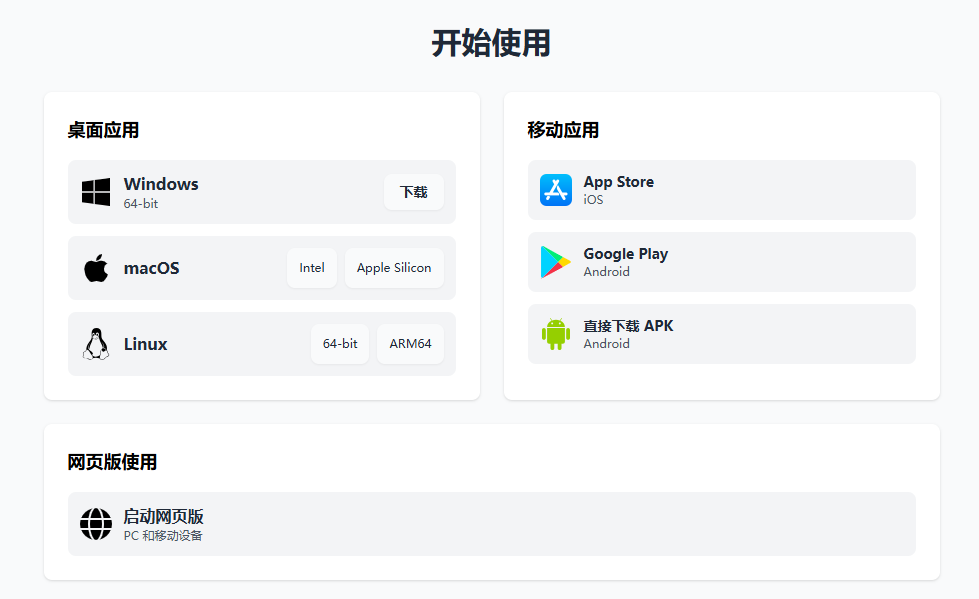
安装chatbox
进入Chatbox官网,点击下载后,选择对应电脑系统进行下载安装
模型设置
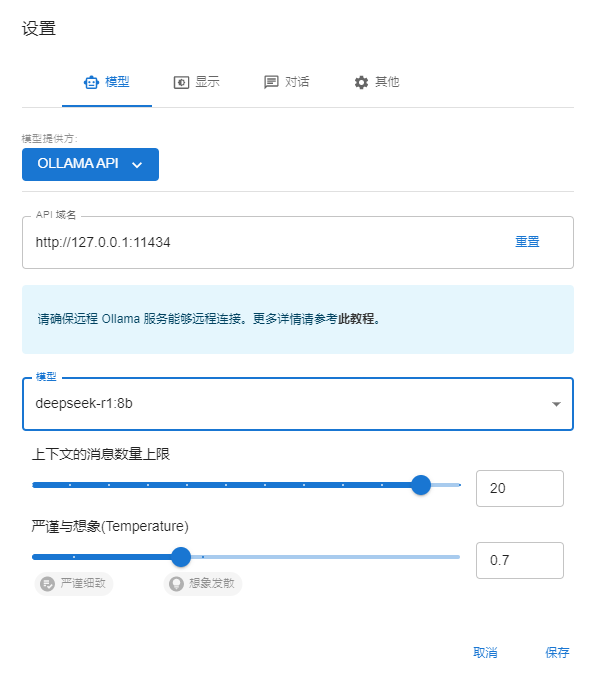
打开安装好后的chatbox,点击设置,将模型提供方选择为OLLAMA API,模型中会自动加载在ollama中下载部署好的模型。
使用
参考
喜欢这篇文章的人也看了

评论
匿名评论隐私政策

